Interesting developments this week as HP, Intel and Yahoo (annointed the title "Yahooptel" by Allistair Croll--see GigaOm post linked later) announce a collaboration to build a cloud targeted at academic and research organizations. Defined, perhaps, as a grid service cloud, the offering is well documented by the aforementioned GigaOm post, William Vambenepe, and the world, so I won't go into too much detail here.
However, I do think there is an interesting little trend here, noted by Stacy in her GigaOm post. Google and IBM, along with Yahooptel are pushing into academic circles for--at least in part--a very interesting reason: to allow computer science and IT Management students to gain experience building applications in so-called Internet scale architectures. The battle for young minds has begun, and the big dogs have a huge advantage here.
Now, there is an interesting counter force at work that will temper any chance of "total domination" by the large established players; the most successful cloud computing is based, at least in part, on open source. So the architectures that tomorrow's SaaS superstars deploy may be heavily influenced by a large vendor, but the frameworks, languages, interfaces, protocols and perhaps even services will be freely available from an open source project and/or vendor.
This is the beauty of open source in the cloud, at least for software. It firmly removes any great advantage to being an established player in the preceding market. The code it takes to build the next generation architecture becomes free and accessible, meaning anyone can get their hands on it.
Hardware, on the other hand, is still expensive to assemble in large configurations. I think this is the real driver for these academic clouds--not necessarily to lock in proprietary software approaches for cloud computing, but certainly to sell a hardware platform. Isn't that half the battle for a high-scale system developer's soul?
Thursday, July 31, 2008
Thursday, July 24, 2008
Cloud Outages, and Why *You* Have To Design For Failure
I haven't posted for a while because I have been thinking...a lot...about cloud computing, inevitable data center outages, and what it means to application architectures. Try as I might to put the problem on the cloud providers, I keep coming back to one bare fact; the cloud is going to expose a lot of the shortcomings of today's distributed architectures, and this time it's up to us to make things right.
It all started with some highly informative posts from the Data Center Knowledge blog chronicling outages at major hosting companies, and failures that helped online companies learn important lessons about scaling, etc. As I read these posts, the thought that struck my mind was, "Well, of course. These types of things are inevitable. Who could possibly predict every possible negative influence on an application, much less a data center." I've been in enough enterprise IT shops to know that even the very best are prepared for something unexpected to happen. In fact, what defines the best shops are that they assume failure and prepare for it.
Then came the stories of disgruntled employees locking down critical information systems or punching the emergency power kill switch on their way out the door. Whether or not you are using the cloud, human psychology being what it is, we have to live every day with immaturity or even just plain insanity.
Yet, each time one of the big name cloud vendors has an outage--Google had one, as did Amazon a few times, including this weekend--there are a bunch of IT guys crying out, "Well, there you go. The cloud is not ready for production."
Baloney, I say. (Well, I actually use different vocabulary, but you get the drift.) Truth is, the cloud is just exposing people's unreasonable expectations for what a distributed, disparate computing environment provides. The idea that some capacity vendor is going to give you 100% up time for years on end--whether they promised it or not--is just delusional. Getting angry at your vendor for an isolated incident or poo-pooing the market in general just demonstrates a lack of understanding of the reality of networked applications and infrastructure.
If you are building an application for the Internet--much less the cloud--you are building a distributed software system. A distributed system, by definition, relies on a network for communication. Some years ago, Sun's Peter Deutsch and others at Sun postulated a series of fallacies that tend to be the pitfalls that all distributed systems developers run into at one time or another in their career. Hell, I still have to check my work against these each and every time I design a distributed system.
Key among these is the delusion that the network is reliable. It isn't, it never has been, and it never will be. For network applications, great design is defined by the application or application system's ability to weather undesirable states. There are a variety of techniques for achieving this, such as redundancy and caching, but I will dive into those in more depth in a later post. (A great source for these concepts is http://highscalability.com.)
Some of the true pioneers in the cloud realized this early. Phil Wainwright notes that Alan Williamson of Mediafed made what appears to be a prescient decision to split their processing load between two cloud providers, Amazon EC2/S3 and FlexiScale. Even Amazon themselves use caching to mitigate S3 outages on their retail sites (see bottom of linked post for their statement).
Michael Hickins notes in his E-Piphanies blog that this may be an amazing opportunity for some skilled entrepreneurs to broker failure resistance in the cloud. I agree, but I think good distributed system hygiene begins at home. I think the best statement is a comment I saw on ReadWriteWeb:
So, in a near future post I'll go into some depth about what you can do to utilize a "cloud oriented architecture". Until then, remember: Only you can prevent distributed application failures.

It all started with some highly informative posts from the Data Center Knowledge blog chronicling outages at major hosting companies, and failures that helped online companies learn important lessons about scaling, etc. As I read these posts, the thought that struck my mind was, "Well, of course. These types of things are inevitable. Who could possibly predict every possible negative influence on an application, much less a data center." I've been in enough enterprise IT shops to know that even the very best are prepared for something unexpected to happen. In fact, what defines the best shops are that they assume failure and prepare for it.
Then came the stories of disgruntled employees locking down critical information systems or punching the emergency power kill switch on their way out the door. Whether or not you are using the cloud, human psychology being what it is, we have to live every day with immaturity or even just plain insanity.
Yet, each time one of the big name cloud vendors has an outage--Google had one, as did Amazon a few times, including this weekend--there are a bunch of IT guys crying out, "Well, there you go. The cloud is not ready for production."
Baloney, I say. (Well, I actually use different vocabulary, but you get the drift.) Truth is, the cloud is just exposing people's unreasonable expectations for what a distributed, disparate computing environment provides. The idea that some capacity vendor is going to give you 100% up time for years on end--whether they promised it or not--is just delusional. Getting angry at your vendor for an isolated incident or poo-pooing the market in general just demonstrates a lack of understanding of the reality of networked applications and infrastructure.
If you are building an application for the Internet--much less the cloud--you are building a distributed software system. A distributed system, by definition, relies on a network for communication. Some years ago, Sun's Peter Deutsch and others at Sun postulated a series of fallacies that tend to be the pitfalls that all distributed systems developers run into at one time or another in their career. Hell, I still have to check my work against these each and every time I design a distributed system.
Key among these is the delusion that the network is reliable. It isn't, it never has been, and it never will be. For network applications, great design is defined by the application or application system's ability to weather undesirable states. There are a variety of techniques for achieving this, such as redundancy and caching, but I will dive into those in more depth in a later post. (A great source for these concepts is http://highscalability.com.)
Some of the true pioneers in the cloud realized this early. Phil Wainwright notes that Alan Williamson of Mediafed made what appears to be a prescient decision to split their processing load between two cloud providers, Amazon EC2/S3 and FlexiScale. Even Amazon themselves use caching to mitigate S3 outages on their retail sites (see bottom of linked post for their statement).
Michael Hickins notes in his E-Piphanies blog that this may be an amazing opportunity for some skilled entrepreneurs to broker failure resistance in the cloud. I agree, but I think good distributed system hygiene begins at home. I think the best statement is a comment I saw on ReadWriteWeb:
"People rankled about 5 hours of downtime should try providing the same level of service. In my experience, it's much easier to write-off your own mistakes (and most organizations do), than it is to understand someone else's -- even when they're doing a better job than you would."Amen, brother.
So, in a near future post I'll go into some depth about what you can do to utilize a "cloud oriented architecture". Until then, remember: Only you can prevent distributed application failures.

Off Topic: The Best Way to Serve You, The Reader
I want to ask you, my readers, a question. Would you find it more valuable to have The Wisdom of Clouds managed more like Nick Carr's RoughType or Matt Asay's Open Road?
Let me explain. As you can see, I've been posting less frequently of late. This is due in part to the increasing velocity of my day job, but it is also due to my increasing use of del.icio.us to highlight posts of interest. Using Feedburner, I can automatically post the links I collect in a given day as an entry in my feed. So, I post essays when the mood and my schedule allow, but I regularly direct my feed subscribers to interesting cloud computing content.
I generally like this approach, except for the fact that the links posts are lost to those readers that actually come to my site, and are also not picked up by Google or other search engines. It is impossible to comment on those link posts as well. Plus, writing the longer essays takes significant time, I usually need to write them all in one sitting to keep them remotely coherent, and thus finding time in the schedule gets harder and harder.
For the last couple of months, I have been working with (well, for, really) Matt Asay, a very successful blogger in the open source community. Matt's approach is to write several short but sweet posts every day, with only the very occasional in depth analysis post. His goal is to be the one place to go for open source news.
My goal is a little bit different. I want to call out the trends and issues related to cloud computing, as well as to make some bold (and, at times, foolish) predictions about what is being overlooked or undervalued in the hype surrounding the topic. So, I don't see myself posting as frequently as Matt, but I wonder if perhaps I should drop the del.icio.us approach, and actually write short but sweet posts about each link or group of related links. It may be a little more time intensive for me, but I would have searchable content, and I would get out smaller samples of my thinking more frequently.
The cost, potentially, would be fewer of the in depth posts that I have come to be known for...though at this point the word "fewer" is relatively meaningless as I have been posting so infrequently anyway. I still want to do the in depth posts, but they may become more like summary analysis of trends from earlier posts than the "out of the blue" analysis I have been doing. Less like Nick Carr, in other words.
What do you think? Is a change in order. Would you like to see more information more often, or deeper analysis on a one or two posts a week on average pace? Are you happy with the del.icio.us for subscribers approach, or do you want a more permanent and interactive approach towards that type of content?
Any feedback I can get (either in the comments below, or by email to jurquhart at yahoo dot com) would be greatly and gratefully appreciated.
Let me explain. As you can see, I've been posting less frequently of late. This is due in part to the increasing velocity of my day job, but it is also due to my increasing use of del.icio.us to highlight posts of interest. Using Feedburner, I can automatically post the links I collect in a given day as an entry in my feed. So, I post essays when the mood and my schedule allow, but I regularly direct my feed subscribers to interesting cloud computing content.
I generally like this approach, except for the fact that the links posts are lost to those readers that actually come to my site, and are also not picked up by Google or other search engines. It is impossible to comment on those link posts as well. Plus, writing the longer essays takes significant time, I usually need to write them all in one sitting to keep them remotely coherent, and thus finding time in the schedule gets harder and harder.
For the last couple of months, I have been working with (well, for, really) Matt Asay, a very successful blogger in the open source community. Matt's approach is to write several short but sweet posts every day, with only the very occasional in depth analysis post. His goal is to be the one place to go for open source news.
My goal is a little bit different. I want to call out the trends and issues related to cloud computing, as well as to make some bold (and, at times, foolish) predictions about what is being overlooked or undervalued in the hype surrounding the topic. So, I don't see myself posting as frequently as Matt, but I wonder if perhaps I should drop the del.icio.us approach, and actually write short but sweet posts about each link or group of related links. It may be a little more time intensive for me, but I would have searchable content, and I would get out smaller samples of my thinking more frequently.
The cost, potentially, would be fewer of the in depth posts that I have come to be known for...though at this point the word "fewer" is relatively meaningless as I have been posting so infrequently anyway. I still want to do the in depth posts, but they may become more like summary analysis of trends from earlier posts than the "out of the blue" analysis I have been doing. Less like Nick Carr, in other words.
What do you think? Is a change in order. Would you like to see more information more often, or deeper analysis on a one or two posts a week on average pace? Are you happy with the del.icio.us for subscribers approach, or do you want a more permanent and interactive approach towards that type of content?
Any feedback I can get (either in the comments below, or by email to jurquhart at yahoo dot com) would be greatly and gratefully appreciated.
Wednesday, July 16, 2008
Watch out for Cisco, kids!
What is the most important enabler of distributed computing architectures, such as cloud oriented architectures? What is the one thing that has to be in ample supply before the other elements of the data center come into play? Is it the number of servers or CPU power available for computing? Is it the size and speed of the disks and network storage devices? Is it the distributed software architectures themselves?
My answer? None of the above. It's network bandwidth, baby, all the way.
Why? Well, let's break down where the costs of distributed systems lay. We all know that CPU capabilities double roughly every couple of years, and we also know that disk I/O slows those CPUs down, but not at the rate that network I/O typically does. When designing distributed systems, you must first be aware of network latency and control traffic between components to have any chance in heck of meeting rigorous transaction rate demands. The old rule at Forte Software, for what it's worth, was:
What is exciting about today's environment, however, is that network technology is changing rapidly. Bandwidth speeds are increasing quickly (though not as fast as CPU speeds), and this high speed bandwidth is becoming more ubiquitous world wide. Inter-data-center speeds are increasingly mind boggling, and WAN optimization apparently has removed much of the fear of moving real-time traffic between geographically disparate environments.
All of this is a huge positive to cloud oriented architectures. When you design for the cloud, you want to focus on a few key things:
Oh, and one more thing. The network is the first element of your data center that sees load, failure and service level compliance. Think about it--without the eyes of the network, all of your other data center elements become black boxes (though often physically with those annoying beeps and little blinking orange lights). What are the nerves in the data center nervous system? Network cables, I would say.
Today I saw two really good posts about possible network trends driven by the cloud, and how Cisco's new workhorse leverages "virtualized" bandwidth and opens the door to commodity cloud capacity. The first is a post by Douglas Gourlay of Cisco, which simply looks at the trends that got us to where we are today, and further trends that will grease the skids for commodity clouds. I am especially interested in the following observations:
Oh, and I wouldn't be surprised if Google, Microsoft, et al. agreed (though not necessarily as Cisco customers).
Does Nexus work? I have no idea. But I am betting that, as private clouds are built, the idea that servers are the center of the universe will be tested greatly, and the incredibly important role of the network will become more and more apparent. And when it does, Cisco may have positioned themselves to take advantage of the fun that follows.
Its just too bad that it is another single-vendor, closed source vendor offering that will take probably 5-7 years (minimum) to replicate in the open source world. At the very least, I hope Cisco is paying attention to Doug's observation that:
However, I would rather have this technology in a proprietary form than not at all, so way to go Cisco, and I will be watching you closely--via the network, of course.
My answer? None of the above. It's network bandwidth, baby, all the way.
Why? Well, let's break down where the costs of distributed systems lay. We all know that CPU capabilities double roughly every couple of years, and we also know that disk I/O slows those CPUs down, but not at the rate that network I/O typically does. When designing distributed systems, you must first be aware of network latency and control traffic between components to have any chance in heck of meeting rigorous transaction rate demands. The old rule at Forte Software, for what it's worth, was:
- First reduce the number of messages as much as possible
- Then reduce the size of those messages as much as possible
What is exciting about today's environment, however, is that network technology is changing rapidly. Bandwidth speeds are increasing quickly (though not as fast as CPU speeds), and this high speed bandwidth is becoming more ubiquitous world wide. Inter-data-center speeds are increasingly mind boggling, and WAN optimization apparently has removed much of the fear of moving real-time traffic between geographically disparate environments.
All of this is a huge positive to cloud oriented architectures. When you design for the cloud, you want to focus on a few key things:
Software fluidity - The ability of the software to run cleanly in a dynamic infrastructure, where the server, switch port, storage and possibly even the IP address changes day by day or minute by minute.
Software optimization - Because using a cloud service costs money, whether billed by the CPU hour, the transaction or the number of servers used, you want to be sure you are getting your money's worth when leveraging the cloud. That means both optimizing the execution profile of your software, and the use of external cloud services by the same software.
Scalability - This is well established, but clearly your software must be able to scale to your needs. Ideally, it should scale infinitely, especially in environments with highly unpredictable usage volume (such as the Internet).
Oh, and one more thing. The network is the first element of your data center that sees load, failure and service level compliance. Think about it--without the eyes of the network, all of your other data center elements become black boxes (though often physically with those annoying beeps and little blinking orange lights). What are the nerves in the data center nervous system? Network cables, I would say.
Today I saw two really good posts about possible network trends driven by the cloud, and how Cisco's new workhorse leverages "virtualized" bandwidth and opens the door to commodity cloud capacity. The first is a post by Douglas Gourlay of Cisco, which simply looks at the trends that got us to where we are today, and further trends that will grease the skids for commodity clouds. I am especially interested in the following observations:
"8) IP Addressing will move to IPv6 or have IPv4 RFCs standardized that allow for a global address device/VM ID within the addressing space and a location/provider sensitive ID that will allow for workload to be moved from one provider to another without changing the client’s host stack or known IP address ‘in flight’. Here’s an example from my friend Dino.9) This will allow workload portability between Enterprise Clouds and Service Provider Clouds.
10) The SP community will embrace this and start aggressively trying to capture as much footprint as possible so they can fill their data centers to near capacity allowing for them to have the maximum efficiency within their operation. This holds to my rule that ‘The Value of Virtualization is compounded by the number of devices virtualized’.
11) Someone will write a DNS or a DNS Coupled Workload exchange. This will allow the enterprise to effectively automate the bidding of workload allocation against some number or pool of Service Providers who are offering them the compute, storage, and network capacity at a given price. The faster and more seamless the above technologies make the shift of workload from one provider to another the simpler it is in the end for an exchange or market-based system to be the controlling authority for the distribution of workload and thus $$$’s to the provider who is most capable of processing the workload."
The possibility that IP addresses could successfully travel with their software payloads is incredibly powerful to me, and I think would change everything for both "traditional" VM users, as well as the virtual appliance world. The possibility that my host name could travel with my workload, even as it is moved in real time from one vendor to another is, of course, cloud computing nirvana. To see someone who obviously knows something about networking and networking trends spell out this possibility got my attention.
(Those who see a fatal flaw in Doug's vision are welcome to point it out in the comments section below, or on Doug's blog.)
The second post is from Hurwitz analyst, Robin Bloor, who describes in brilliant detail why Cisco's Nexus 7000 series is different, and why it could very well take over the private cloud game. As an architecture, it essentially makes the network OS the policy engine for controlling provisioning and load balancing, though with bandwidth speeds that blow away today's standards (10G today, but room for 40G and 100G standards in the future). Get to those speeds, and all of a sudden something other than network bandwidth is your restricting function in scaling a distributed application.
I have been cautiously excited about the Nexus announcement from the start. Excited because the vision of what Nexus will be is so compelling to me, for all of the reasons I describe above. (John Chambers, CEO of Cisco, communicates that vision in a video that accompanied the Nexus 5000 series launch.) Cautious, because it reeks of old-school enterprise sales mentality, with Cisco hoping to "own" whole corporate IT departments by controlling both how software runs, and what hardware and virtualization can be bought to run it on. Lock-in galore, and something the modern, open source aware corporate world may be a little uneasy about.
That being said, as Robin put it, "In summary: The network is a computer. And if you think that’s just a smart-ass bit of word play: it’s not."
Robin further explains Cisco's vision as follows:
Would all applications run this way? Probably not. But those mission critical, highly distributed, performance-is-everything apps you provide for your customers, or partners, or employees, or even large data sets, are extremely good candidates for this way of thinking."Cisco’s vision, which can become reality with the Nexus, is of a data center that is no longer defined by computer architecture, but by network architecture. This makes sense on many levels. Let’s list them in the hope of making it easier to understand.
- Networks have become so fast that in many instances it is practical to send the the data to the program, or to send the program to the data, or to send both the program and the data somewhere else to execute. Software architecture has been about keeping data and process together to satisfy performance constraints. Well Moore’s Law reduced the performance issue and Metcalfe’s Law opened up the network. All the constraints of software architecture reduced and they continue to reduce. Distributing both software and data becomes easier by the year.
- Software is increasingly being delivered as a service that you connect to. And if it cannot deliver the right performance characteristics in the place where it lives, you move it to a place where it can.
- Increasingly there is more and more intelligence being placed on the switch or on the wire. Of course Cisco has been adding intelligence to the switch for years. Those Cisco firewalls and VPNs were exactly that. But also, in the last 5 years, agentless sotware (for example some Intrusion Detection products) has become prominent. Such applications simply listen to the network and initiate action if they “don’t like what they hear”. The point is that applications don’t have to live in server blade cabinets. You can put them on switches or you could put them onto server boards that sit in a big switch cabinet. They’re very portable.
- The network needs an OS (or NOS). Whether Cisco has the right OS is a point for debate, but the network definitely needs an OS and the OS needs to perform the functions that Cisco’s NX-OS carries out. It also needs to do other things to like optimize and load balance all the resources in a way that corresponds to the service level needs of the important business transactions and processes it supports. Personally, I do not see how that OS can do anything but span the whole network - including the switches."
Oh, and I wouldn't be surprised if Google, Microsoft, et al. agreed (though not necessarily as Cisco customers).
Does Nexus work? I have no idea. But I am betting that, as private clouds are built, the idea that servers are the center of the universe will be tested greatly, and the incredibly important role of the network will become more and more apparent. And when it does, Cisco may have positioned themselves to take advantage of the fun that follows.
Its just too bad that it is another single-vendor, closed source vendor offering that will take probably 5-7 years (minimum) to replicate in the open source world. At the very least, I hope Cisco is paying attention to Doug's observation that:
"[T]here will be a standardization of the hypervisor ‘interface’ between the VM and the hypervisor. This will allow a VM created on Xen to move to VMWare or Hyper-V and so on."I hope they are openly seeking to partner with OVF or another virtualization/cloud standard to ensure portability to and from Nexus.
However, I would rather have this technology in a proprietary form than not at all, so way to go Cisco, and I will be watching you closely--via the network, of course.
Monday, July 07, 2008
Cloudware: Standard to Watch, or Another Self-Interested Enterprise Play
Rich Miller of Replicate Technologies, Inc. and Telematique fame wrote a post the other day that explored 3TERA's Cloudware vision with a highly critical eye:
Right there is the crux of the argument for open source standards versus simply open standards. I briefly interviewed for a position with a giant software company to be a representative on various SOA standards bodies. The focus of that team was to promote their engineer's solutions to the rest of the body, and to master the art of negotiating the best position possible for that technology. In other words, if the company invented it, it was this team's job to turn it into a standard, or at least make sure the adopted standard would support their technology or protocols. The traditional standards game is one of diplomacy, negotiation and gamesmanship largely because it is an environment where vendors are pitting their self-interests against each other.
For 3TERA to base Cloudware on AppLogic's existing architecture and functionality is purely self-interest on 3TERA's part. If they had wanted to promote openness equally among potential vendors, they would open source AppLogic outright, and switch to a solid open source business model. Alternatively, they would throw significant resources and IP into an existing open source project. To "open" their own architecture (and therefore forcing others to conform to it), but not sharing the implementation, is simply driving competitive advantage for themselves.
This is why I think you saw such quick refutement of supposed support for Cloudware when the erroneous Forbes article was published about the effort. (Again, this was not 3TERA's fault, and Bert should not be blamed for this error.) The other cloud management and provider platform companies are rightfully eyeing this with some skepticism, many saying outright that they have faith that the standard will appear through market forces.
I almost hate to write this post, because it inevitably reflects badly on 3TERA, and I am actually a huge admirer of their product marketing. Bert set the stage for "private clouds"--though he didn't use that term--even when my employer at the time had a perfectly viable solution, but was struggling to find the right message for the right audience. Their demonstration of moving an entire virtual data center with a single command can't be beat. As far as I know, they have had great success (relative to others) in the hosting space, but have not yet penetrated the larger enterprises (though they are trying). In truth, the hosting story alone is why I think they are the only ones that can claim some portability for end customers.
(There are reportedly issues with the scalability of the platform, but I have no proof of that other than 2nd hand information from former Cassatt customers that tried and rejected 3TERA. Besides, scalability issues can always be fixed in future releases.)
Cloudware, however, bugs me to no end, and I hope 3TERA will either turn it into a legitimate open source project (based on the AppLogic code) or spare us the pain of vendor brinkmanship and offer Cloudware as an AppLogic specific framework, but not an open standard.
By the way, I would have had that standards body diplomat role if I was willing to move north...
Update 7/8/2008: William Vanbenepe points out in the comments below that there is an existing set of threads about Cloudware on his blog and John William's blog. The comments to these blogs are worth a read, as they lay out the debate from all sides.
"In September of last year, as I was preparing (mentally and emotionally) to get Replicate started on its current path, I considered issues of portability and interoperability in the virtualized datacenter. I posted a few comments about OVF but one in particular drew the attention of Bert Armijo of 3tera.Bert responded in the comments:
At that time, Bert indicated that he thought it "... too early for a standard,...", with a (perfectly arguable) claim that standards are often "... a trade-off to gain interoperability in exchange for stifling innovation." He went on to say that "(w)e haven't adequately explored the possibilities in utility computing." He then provided a critique of OVF. (Whether I agree with that critique or not is immaterial to this post, and the subject for another time.)
At the end of June, 3tera announced their Cloudware vision for a standards-based interoperable utility infrastructure. Since the arrival of Cloudware, there have been a number of venues at which "cloud computing" and interoperability has been on the minds of the cognoscenti... Structure08 and Velocity being the most heavily covered. In the past few weeks, there have also been claims, and counter-claims of support... and to be fair, the disputed claims of support were made by others, not by 3tera.
So... what's changed, Bert? Why is "now the time" to create the standard for interoperable cloud computing? What's happened in 9 - 10 months that has so changed the field, that these efforts don't also stifle innovation?"
"Last year what most people meant when they talked about a standard for "cloud computing" was a portable virtual machine format. While that's important, it's not cloud computing. What's changed in the past 10 months is that there are now a number of companies offering workable services that have a vision beyond merely hosting virtual machines."That would be a wonderful explanation, if it wasn't for the fact that Bert is blatantly using Cloudware to promote 3TERA's AppLogic as the core architecture of the "standard". Here is what Larry Dignan of ZDNet's Between the Lines reported when Bert first hinted about Cloudware:
"Initially, 3Tera’s AppLogic software will play a prominent role in the Cloudware Architecture, but that’s because these efforts initially need at least one vendor championing the effort."In other words, AppLogic gets a huge head start, defines what the platform should look like, do and not do, etc., and uses Cloudware as a vehicle to thrust itself into the "de facto standard" spot for (at the very least) infrastructure clouds (aka HaaS).
Right there is the crux of the argument for open source standards versus simply open standards. I briefly interviewed for a position with a giant software company to be a representative on various SOA standards bodies. The focus of that team was to promote their engineer's solutions to the rest of the body, and to master the art of negotiating the best position possible for that technology. In other words, if the company invented it, it was this team's job to turn it into a standard, or at least make sure the adopted standard would support their technology or protocols. The traditional standards game is one of diplomacy, negotiation and gamesmanship largely because it is an environment where vendors are pitting their self-interests against each other.
For 3TERA to base Cloudware on AppLogic's existing architecture and functionality is purely self-interest on 3TERA's part. If they had wanted to promote openness equally among potential vendors, they would open source AppLogic outright, and switch to a solid open source business model. Alternatively, they would throw significant resources and IP into an existing open source project. To "open" their own architecture (and therefore forcing others to conform to it), but not sharing the implementation, is simply driving competitive advantage for themselves.
This is why I think you saw such quick refutement of supposed support for Cloudware when the erroneous Forbes article was published about the effort. (Again, this was not 3TERA's fault, and Bert should not be blamed for this error.) The other cloud management and provider platform companies are rightfully eyeing this with some skepticism, many saying outright that they have faith that the standard will appear through market forces.
I almost hate to write this post, because it inevitably reflects badly on 3TERA, and I am actually a huge admirer of their product marketing. Bert set the stage for "private clouds"--though he didn't use that term--even when my employer at the time had a perfectly viable solution, but was struggling to find the right message for the right audience. Their demonstration of moving an entire virtual data center with a single command can't be beat. As far as I know, they have had great success (relative to others) in the hosting space, but have not yet penetrated the larger enterprises (though they are trying). In truth, the hosting story alone is why I think they are the only ones that can claim some portability for end customers.
(There are reportedly issues with the scalability of the platform, but I have no proof of that other than 2nd hand information from former Cassatt customers that tried and rejected 3TERA. Besides, scalability issues can always be fixed in future releases.)
Cloudware, however, bugs me to no end, and I hope 3TERA will either turn it into a legitimate open source project (based on the AppLogic code) or spare us the pain of vendor brinkmanship and offer Cloudware as an AppLogic specific framework, but not an open standard.
By the way, I would have had that standards body diplomat role if I was willing to move north...
Update 7/8/2008: William Vanbenepe points out in the comments below that there is an existing set of threads about Cloudware on his blog and John William's blog. The comments to these blogs are worth a read, as they lay out the debate from all sides.
Sunday, July 06, 2008
Which Sun Do You Orbit?
I love cloud computing. I love the concept, I love many of the implementations, and I love the opportunity that such a major disruption creates for entrepreneurs and tech giants alike. There is much to be excited about, though the market is in its infancy.
Or markets, if you look closely. Simon noted that at his Opscon presentation this year he ended up on the receiving end of an extended diatribe from a gentleman who was arguing determinately that software would never be portable between Amazon EC2 and Google AppEngine (which is probably very true). Simon's response was right on the money: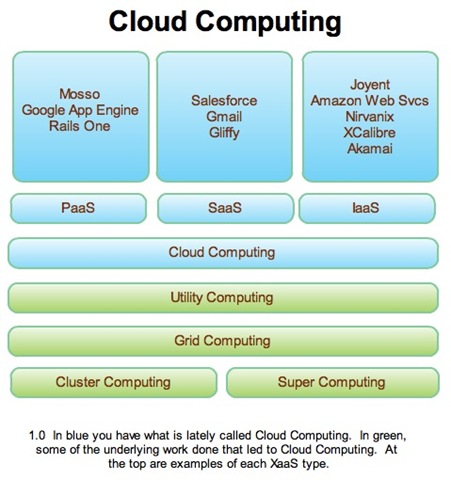
Or markets, if you look closely. Simon noted that at his Opscon presentation this year he ended up on the receiving end of an extended diatribe from a gentleman who was arguing determinately that software would never be portable between Amazon EC2 and Google AppEngine (which is probably very true). Simon's response was right on the money:
"I must admit I was somewhat perplexed at why this person ever thought they would and why they were talking to me about it. I explained my view but I also thought that I'd reiterate the same points here.From the ideas of componentisation, the software stack contains three main stable layers of subsystems from the application to the framework to hardware. This entire software stack is shifting from a product to a service based economy (due to commoditisation of IT) and this will eventually lead to numerous competitive utility computing markets based upon open sourced standards at the various layers of this stack.
These markets will depend upon substitutability (which includes portability and interoperability) between providers. For example you might have multiple providers offering services which match the open SDK of Google App Engine or another market with providers matching Eucalyptus. What you won't get is substitutability from one layer of the stack (e.g. the hardware level where EC2 resides) to another (e.g. the framework level where GAE resides). They are totally different things: apples and pears."
I want to take Simon's "stack" theory and refine it further. Look at the layers of the stack, and note that there appears to be a relatively small number of companies in each that can actually drive a large following to their particular set of "standards". In the platform space, of course Google's python-focused (for now) restricted library set is where much of the focus is, but no one has counted out Bungie Labs yet, nor is anyone ignoring what Yahoo might do in this space. Each vendor has their framework (as Simon rightly calls the platform itself), but each has a few followers building tools, extensions, replications and other projects aimed at both benefiting from and extending the benefits of the platform. The diagram below identifies many of the current central players, or "suns", that exist in each technology stack today:
Credit: Kent Langley, ProductionScale
I call these communities of central players and satellites "solar systems" (though perhaps it would be more accurate to call them "nodes and edges", as we will see later).
In each solar system--say the Google AppEngine solar system--you will find an enthusiastic community of followers who thoroughly learn the platform, push its limits, and frequently (though not in every case) find economic and productivity benefits that keep them coming back. Furthermore, the most successful satellite projects will attract their own satellites, and an ever changing environment will form, though the original central players will likely maintain their role for decades (basically until the market is disrupted by an even better technical paradigm).
You already see a very strong Amazon system forming. RightScale, Enomalism and ELASTRA, are all key satellites to AWS's sun. Now you are even starting to hear about satellites of satellites in that space, such as GigaSpace's partnership with RightScale. However, if you look closely at this system, you begin to see the breakdown in the strict interpretation of this analogy, as several of the players (CohesiveFT's ElasticServer On-Demand, for example) starting to address multiple suns in a particular "stack". Thus my earlier comment that perhaps a nodal analogy is somewhat better.
The key here is that for some time from now, technologies created for the cloud will be attached to one or two so-called solar systems in the stack the technology addresses. Slowly standards will start to appear (as one solar system begins to dominate or subsume the others), and eventually the stack will play as a commodity market, though (I would argue) still centered around one key player. By the time this happens, some cross pollination of the stacks themselves will start happen (as has already happened with the prototype of GAE running in EC2), at which point new gaps in standards will be identified. This is going to take probably two decades to play out entirely, at which point the cloud market will probably already face a major disruptive alternative (or "reinvention").
I say this not to be cynical nor to pontificate for pontification's sake. I say this because I believe developers are already starting to choose their "solar system", and thus their technological options are already being dictated by which satellite technologies apply to their chosen sun. Recognizing this as OK, in fact natural to the process, and acknowledging that religious wars between platforms--or at least stacks--is kind of pointless, will make for a better climate to accelerate the consolidation of technical platforms into a small set of commodity markets. Then the real fun begins.
Of course, I'm a big fan of religious wars myself...
Thursday, July 03, 2008
Is Amazon Google's biggest threat?
This is a bit of a stretch, but a Greg Linden post, "Amazon page recommendations", suggests that Amazon may be offering a new service soon, one that could turn Amazon into one of the core information sources on the Internet. Greg points to a post by Brady Forrest of O'Reilly Radar that outlines the service in more detail.
From Brady's post:
From Brady's post:
"Amazon is turning its personalization engine towards webpages. You can test it on your site via the new Page Recommender Widget (sorry if the link doesn't work you, it's only open to affiliates). The widget only considers pages on your website. As you can see from the screenshot above, it shows a combination of products and webpages.Amazon provides the following info:
In order to generate page recommendations, the Page Recommender Widget must be placed on every page of your site that you'd like to be recommended. Page recommendations will appear in the widget over time, as Amazon analyzes traffic patterns on your site. You'll typically see recommendations for your most popular pages first, with the remainder of your site filling in over time. The length of this time depends on the characteristics of your web site. During this period, we'll still display individually targeted Amazon products in the widget.The widget learns from your visitors and how they move through your site. If you only have a couple of pages the widget won't do much for you. I do not know if the widget restricts recommended pages to the same domain or if all of an affiliate ID's sites will be included. I wonder if a visitor's Amazon history will be used by the Recommendation Engine."
Brady goes on to theorize that this may be the beginnings of a new recommendation web service from Amazon, and I think he may be on to something. Amazon has perhaps the most sophisticated usage tracking software out there on its retail sites, and no one really cares because the data is used to enhance the shopping experience so much. I can imagine that a service which allows any site to determine context and preferences for any given user (or at least the users with Amazon IDs) would be highly profitable.
Now the stretch. Is this building up an extension of human knowledge that not only tracks what information a user seeks, but what they actually use? Given that, is there the long term potential to beat Sergey and Larry to a specialized brain extension, as described in Nick Carr's The Atlantic article, "Is Google Making Us Stupid?":
"Where does it end? Sergey Brin and Larry Page, the gifted young men who founded Google while pursuing doctoral degrees in computer science at Stanford, speak frequently of their desire to turn their search engine into an artificial intelligence, a HAL-like machine that might be connected directly to our brains. “The ultimate search engine is something as smart as people—or smarter,” Page said in a speech a few years back. “For us, working on search is a way to work on artificial intelligence.” In a 2004 interview with Newsweek, Brin said, “Certainly if you had all the world’s information directly attached to your brain, or an artificial brain that was smarter than your brain, you’d be better off.” Last year, Page told a convention of scientists that Google is “really trying to build artificial intelligence and to do it on a large scale.”"Now imagine Amazon actually anticipating your interests before you even realize them consciously simply by tracking the context in which you "live" online. Is that AI enough for you?
Now, Google does some similar tracking with its Web History service, so I'm probably way off here. However, I get the sense that Amazon Web Services is pushing Amazon to think in terms of a larger vision, one in which it plays a central part in any and all commercial activities on the web, making it the smartest marketing machine on the planet--smarter in that sense that even the mighty Google itself.
Subscribe to:
Posts (Atom)